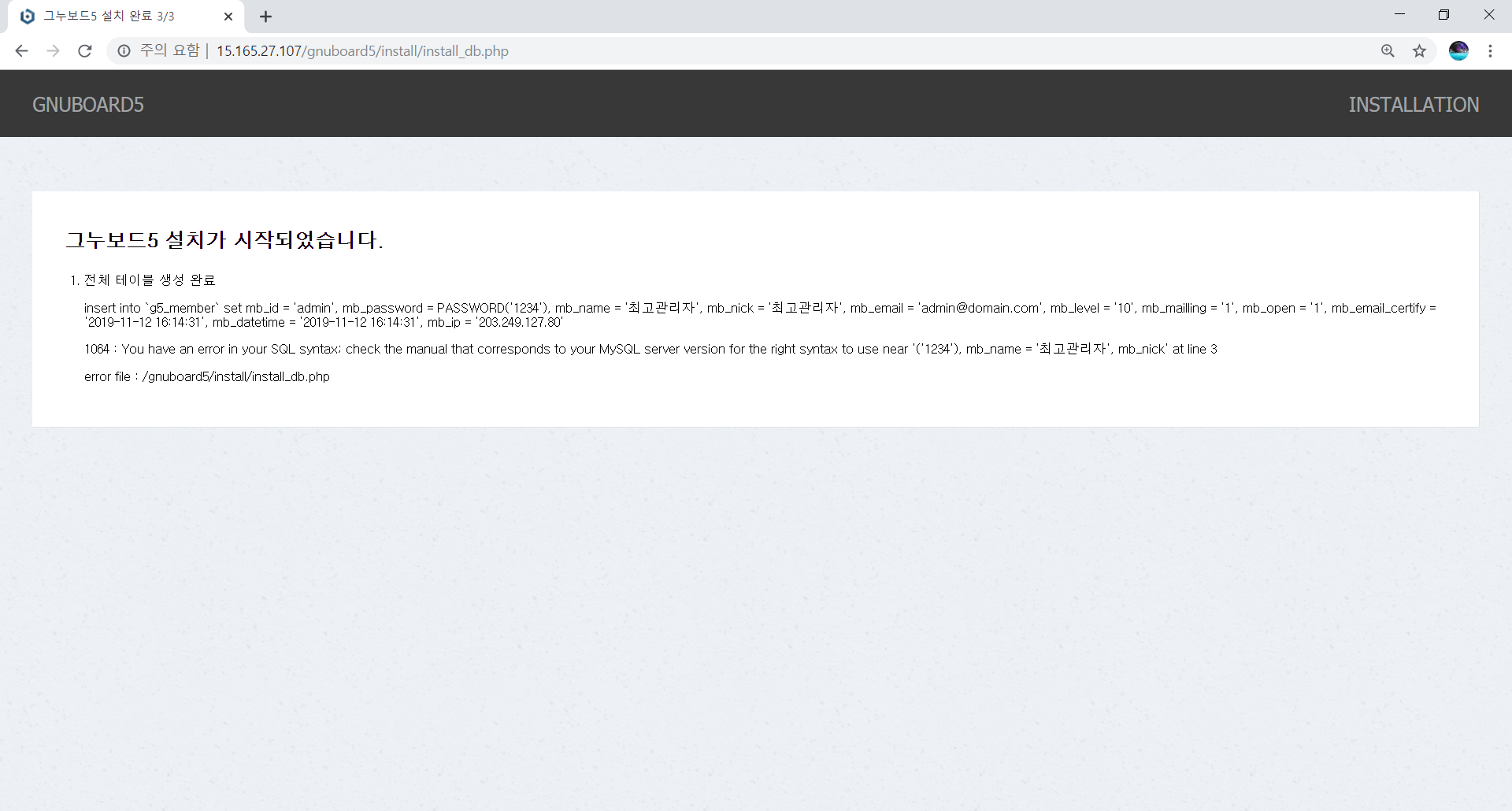
1. 데이터셋
Wajid Mumtaz의 데이터셋
2. 방법론

본 연구는 기본적으로 사용되는 Feature set에 따라 세 부분으로 나뉜다.
8개의 선형 feature(4-band 채널과 반구형 비대칭 4채널),
2개의 비선형 feature(RWE, WE),
6개의 선형 + 비선형 세트 조합
1) 전처리
(1) 뇌파 노이즈 감소
0.5~32Hz 사이의 신호에서 분석이 수행될 수 있도록 고역 필터 및 저역 필터로 필터링 되었다. 근육 움직임이나 전력 노이즈 신호는 32Hz를 초과하기 때문에 이 프로세스에서 제거된다. 눈 깜빡임, 안구 운동과 같은 잡음은 ICA(Independent Component Analysis)를 사용하여 제거하였다.
(2) 특징 추출
- Band Power
델타 (0.5–4Hz), 세타 (4–8Hz), 알파 (8–13Hz) 및 베타 (13–30Hz)의 네 가지 주파수 대역이 EEG에서 추출된다. welch periodogram(웰치 주기도) 를 사용하여 EEG 신호의 전력 스펙트럼을 계산한다. 이 방법은 신호가 50%씩 겹치는 작은 세그먼트로 나뉜다. 수정된 주기도의 평균을 취하여 각 대역의 신호 전력을 얻는다.
-반구형 비대칭
뇌의 왼쪽 절반과 오른족 절반의 뇌파 신호 전략의 차이는 반구간 비대칭으로 나타난다.
- 웨이블릿 변환
웨이블릿 변환은 저주파에서는 좋은 주파수 정보를 제공한다. 웨이블릿 전환을 사용하여 시간-주파수 신호를 얻는다. CWT는 중복성이 높고 계산 시간과 리소스가 크게 필요하기 때문에 이산 웨이블릿 변환(DWT)로 해결한다.
- 상대 웨이블릿 에너지
각 분해능 수준에서 웨이블릿 계수와 관련된 상대 에너지
- 웨이블릿 엔트로피
각 분해능 수준에 포함된 정보는 웨이블릿 엔트로피로 표현된다.
2) Feature 축소
선형 Feature 분석을 위해서, 19개의 Feature(각 채널 위치) 에 대해 1개 Feature의 특징 세트가 사용되었다.
비선형 분석에서 76개의 feature는 계산 비용과 효율성을 위해서 차원 축소 기능을 사용했다. 이에 PCA 를 사용하였다.
3) 분류기 모델
(1) 다중 퍼셉트론 신경망 (MLPNN)
지도 학습을 사용하는 신경망 모델 유형이며 역전파로 훈련되는 Feed forward network. 1개의 입력 레이어, 1개의 출력 레이어 및 2개 이상의 은릭 레이어를 사용한다. 입력 레이어에는 linear 함수를 사용하였고, 출력 레이어와 은릭 레이어에는 sigmoid 와 같은 비선형 함수를 사용하였다.
(2) RFBN
(3) LDA
(4) QDA
4) 검증
분류기는 10배 교차 검증을 100회 반복하여 실행하였다. 혼동 행렬을 기반으로 정확도, 민감도, 특이도가 계싼된다.
3. 결과
1) 밴드 파워
알파 전력이 MLPNN 에서 acc 91.67을 달성
2) 반구형 비대칭
알파 비대칭에 대한 QDA에서 73.33의 분류 정확도
3) 비선형 Feature
RWE : RBFN , WE : LDA에서 각각 90%의 분류 정확도
4) 조합
RWE와 알파 파워의 조합은 정확도: 93.33 민감도 : 94.44 특이도 87.78을 보여주었다.